
Sidste år blev jeg kontaktet af en, der hævdede at have dechifreret Voynich-manuskriptet. Dette manuskript er et af de store gåder fra middelalderens historie og for den sags skyld også for sprogvidenskab. Ingen har endnu været i stand til at dechifrere det, og mange har prøvet. Det er skrevet i et totalt ukendt script på et uidentificeret sprog.
Manuskriptet er mere end 500 år gammelt. Det har været offentligt tilgængeligt i et århundrede, og nu er det også tilgængeligt online. Ingen har været i stand til at oversætte manuskriptet; der har været mange forslag, men alle er blevet afvist. Folk har hævdet, at det kunne være skrevet i en form for hebraisk, på et romansk sprog, i en tidligere form for romani (sigøjnersprog), på et indisk sprog, eller endda på et sprog fra en anden planet. Specialisterne i Middelalder har, kort sagt, ingen anelse. Kryptografer – specialister i hemmelig skrivning – har også brudt deres hjerne på det. Sprogfolk har også prøvet at finde ud hvad der står, men alt har været forgæves.
I dette bidrag vil jeg hævde, at manuskriptet faktisk ikke er interessant for sprognørder.
Som teenager udfordrede en ven og jeg hinanden ved at skrive korte tekster i hemmelige koder, og vi blev bedre og bedre til at dechifrere dem, mens vi også forbedrede vores evner til at gøre vores koder mere komplicerede. Vi har ikke været i stand til at dechifrere Voynich-manuskriptet. Min ven, Eric, blev en bilmekaniker, og jeg blev en sprogforsker. Vi gør nu begge to noget nyttigt for samfundet.

Voynich-manuskriptet er skrevet på pergament, som er dateret til første halvdel af 1400-tallet. Ingen tvivl om datering af det fysiske. Teksten og illustrationer kunne være nyere, men kunne også være fra samme tid. Men bortset fra det, er der kun mysterier tilbage. Hvem skrev manuskriptet? På hvilket sprog? Hvad handler teksten om? Hvad er betydningen eller henvisningen til disse mærkelige tegninger af drager, badende nøgne damer og kort over kendte og ukendte steder? Hvorfor er der ingen rettelser i manuskriptet?
Som sprogforsker er man selvfølgelig nysgerrig efter teksten, og man vil vide, om den er skrevet på et kendt eller ukendt sprog. Da manuskriptet indeholder 288 sider, er det bestemt ikke manglen på materiale, der har hindret fortolkningen af teksten. Til sammenligning blev Linear B, skrevet på et stavelsesskrift som er flere århundreder ældre end det græske alfabet, hovedsagelig afkrypteret på grundlag af korte inskriptioner på lertavler, ikke et manuskript i boglængde.
Hvordan går man til værks med at dechifrere et script og en tekst som den i Voynich-manuskriptet? Man kan bruge antallet af tegn (bogstaver) i teksten, længden på de forskellige ord, kombinationen af tegnene og gentagelse af mønstre som spor. “Ordene” (lad os antage, at de faktisk er ord), er adskilt af mellemrum i manuskriptet (hvilket for øvrig ikke er tilfældet i alle gamle tekster). Man kan antage, at der skal være tilbagevendende dele af ord: f.eks. ville der være endelser på et substantiv (kasus), som man finder dem på russisk, latin og græsk. I begyndelsen af ordene kunne der være afledte præfikser, som vi finder dem på dansk, såsom u-i ”ubehøvlet, ukendt” og be-i ”betale, bebrejde”. Man kunne også forsøge at identificere tilbagevendende nominale markørklasser som på Bantu-sprog, verbale bøjninger såsom engelsk -edi ”walked” or spansk -mosi ”vamos” eller flertalssuffikser som dansk -eri ”substantiver”. Vi ved, at de fleste sprog i verden har dem. Man kan derfor forvente, at sådanne dele af ord i slutningen og måske også begyndelsen ville blive gentaget gennem hele teksten, som i enhver naturlig tekst. Der er kun få sprog, der sætter sådanne elementer midt i et ord.
Først skal man finde ud af, hvilken slags manuskript det er. Man vil gerne finde ud af, om scriptet er et alfabet (i et alfabetisk script tildeles hver talelyd i princippet et bogstavsymbol, som på engelsk, tysk eller spansk, og både vokaler og konsonanter er skrevet, og altid separat), en abugida (hvert symbol betegner en konsonant-vokalkombination, ligesom ka eller si) eller en abjad, et skriftsystem med kun konsonanter (srprsngl, wth nl cnsnnts, nglsh snt tht dffclt t rd), eller et skriftsystem, hvor hvert symbol angiver en betydning. På kinesisk kan ét skriftligt symbol så repræsentere fx “hus” eller “hest” eller “mor”.
Det kinesiske sprog har mange tusinder af sådanne symboler, fordi de hovedsageligt betegner betydninger, stavelsesskrifter har mellem 35 og 100 symboler for stavelser, abjads mellem 15 og 30 konsonantsymboler og alfabeter har omtrent mellem 20 og 30 symboler for vokaler og konsonanter. Antallet af symboler giver således en indikation af, hvilket skriftsystem der bruges.

I Voynich-manuskriptet er der mellem 25 og 30 individuelle symboler, hvilket ville betyde, at det enten er et alfabetisk skrift eller et konsonantisk skrift (abjad), og i sidstnævnte tilfælde ville det være et sprog med mange konsonanter. Hvis det var et alfabetisk script, ville sproget have et ret gennemsnitligt antal talelyde. Det er så den mest sandsynlige alfabetisk. Men er et alfabetisk script mere sandsynligt end andre typer skrift?
Kun abjad- eller abugida-skrivesystemer er sandsynligvis blevet opfundet spontant, men mennesker udvikler aldrig selv et alfabetisk system. Alfabetisk skrivning er faktisk kun blevet opfundet en gang (!) i universet eller i det mindste på jorden (vi mangler stadig data fra andre planeter). Alfabetet med konsonanter og vokaler var en nyskabelse af grækerne, som tilføjede vokaler til et semitisk skriftsystem, der kun repræsenterede konsonanter. Fra det græske alfabet er de romerske (vores), runiske og kyrilliske alfabeter afledt, og lærde er enige om, at selv de helt forskellige Ogham-skrift, armenske og georgiske skrifter blev inspireret af eksisterende alfabeter som dem til græsk eller latin.

Der er også en mulig forbindelse mellem ordlængde og abjads. Hvis alle symboler i skriftet repræsenterer konsonanter, dvs. manuskriptet er en abjad, ville ordene på Voynichs sprog i gennemsnit være ret lange. Faktisk er sekvenserne sandsynligvis i gennemsnit længere end forventet for ethvert sprog skrevet med en abjad. Således er det sandsynligvis ikke en abjad.
Når folk er inspireret til at lave deres eget skriftsystem, laver de typisk et stavelsesskrivesystem, især hvis stavelsesstrukturen er enkel i deres sprog, som når hver konsonant altid følges af en vokal i et ord. Indianerne, cherokeerne, ndyukerne, vai-afrikanerne fra Liberia, sumerere osv., de opfandt alle skriftarter spontant, og de skrev alle enten kun konsonanter, eller, oftere, kun konsonant-vokalkombinationer. Så hvis Voynich er skrevet i et alfabetisk script, oprettes det helt sikkert af en person, der kender alfabetisk skrivning i forvejen, som de bruges til andre sprog. Ellers ville denne person have opfundet et stavelsessystem eller en abjad.

Nu hvor vi har konstateret, at det sandsynligvis er et alfabetisk skrivesystem, ville det næste skridt til at udforske skriftet, være en hypotese om, at teksten er skrevet på et eksisterende eller kendt sprog, men i et andet skrift end normalt. Man antager således, at hvert tegn repræsenterer et bogstav på et eksisterende sprog, men det er blevet translittereret til et andet skrift. Dette er blevet testet for Voynich, og ingen af de mere end 300 sprog, der blev testet, gav et resultat. Man må naturligvis huske, at det er et middelalderligt sprog, som måske har været ganske anderledes end det sprog, det udviklede sig til (middelalderens nederlandsk og engelsk, for eksempel er næsten ulæselige for moderne talere af disse sprog). På den anden side er computere rimeligt gode til at gruppere sprog efter familier baseret på lydsystemer og bogstavfrekvens. De fire sprog, der kom tættest da men testede Voynich (og der er altid sprog, der kommer tættest på) var hebraisk, arabisk, malaysisk skrevet på arabisk skrift og amharisk (et sprog i Etiopien, der er skrevet ved hjælp af et stavelsesskrift). Det lyder så ikke overbevisende. Tre sprogfamilier, og tre skriftarter: det lyder tilfældigt.
Man kan også kontrollere den gennemsnitlige ordlængde. På sprog som grønlandsk er ord for eksempel længere end på europæiske sprog, mens kinesiske ord er meget kortere. Ord, der består af flere dele (f.eks. morfemer som præfikser og suffikser), ligesom grønlandsk, har en tendens til at være længere end dem på sprog med ord, der kun er en stavelse lang, som kinesisk. Den gennemsnitlige ordlængde for Voynich-manuskriptet ser meget ud som på engelsk og latin, hvilket igen antyder, at det ville være skrevet i et alfabet snarere end et abjad, og at sprogtypen ikke er polysyntetisk som grønlandsk og heller ikke analytisk som kinesisk. Tværtimod er ordets længde mere imellem, ligesom europæiske eller mellemøstlige sprog.

Sprogfolk ved også, at nogle talelyde er universelt hyppigere end andre, og at viden om verdens sprog kan bruges til at antyde bogstavernes værdier. Vokallyden /a/ er hyppigere end /e/, og konsonanten /m/ findes på de fleste sprog, men konsonanten /f/ er meget sjældnere. Og så videre. Jeg ved dog ikke noget om eksisterende undersøgelser, der systematisk har brugt denne viden til Voynich-manuskriptet, men nogle mennesker har brugt denne information i hvert fald intuitivt.
En anden mulighed er at se på fordelingen af sproglyde inden for et ord under antagelse af, at hvert bogstavsignal i teksten repræsenterer en sproglyd. Man kan for eksempel forsøge at finde ud af, hvilke bogstaver der sandsynligvis er vokaler og hvilke konsonanter ved at se på hvilke bogstaver eller symboler der findes i ordene. I sprogvidenskab kalder vi dette fonotaks. Der er bogstaver, der kun findes på bestemte positioner, og det er ikke ualmindeligt, at sprog har lyde, der ikke vises i alle positioner i ordet – på de fleste sprog kan ord for eksempel ende i -tk. Distributionen af bogstaver i manuskriptet er undersøgt, og resultaterne synes at pege på muligheden for et naturligt sprog. På den anden side har forskere også observeret, at visse bogstaver er meget hyppigere i nogle dele af teksten, og endda i en sådan grad, at det er mistænkeligt. Dette findes typisk på falske sprog.
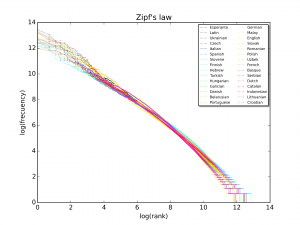
Man kan også undersøge en tekst for at se, om den adlyder Zipfs lov: i 1930’erne observerede George Kingsley Zipf, at der er en sammenhæng mellem ordlængde og ordenes frekvens. Hyppige ord har en tendens til at være kortere på alle sprog. Voynich-teksten overholder også Zipfs lov, hvilket kan antyde, at den faktisk er skrevet på et naturligt sprog. Men da computeranalyser ikke resulterede i en overbevisende match med noget andet sprog, så er det sandsynligvis ikke et kendt sprog med translittererede bogstaver.
Kunne teksten repræsentere en mere kompliceret kode, dvs. en tekst, hvor hvert bogstav erstattes af et andet bogstav, men hvor formen på bogstavet justeres efter en eller anden regel, måske skiftes til en anden kode for hver linje eller hvert afsnit? Dette er blevet afvist af eksperter, da det burde have ført til en nogenlunde lige fordeling af bogstaverne i teksten, og det er helt klart heller ikke tilfældet.
Kort sagt, trods indsatsen fra seriøse kryptografer, middelalderister og lingvister, har ingen lærde eller team af lærde været i stand til at knække koden, ikke engang ved hjælp af kraftige computere.
Og ikke kun lærde mennesker har prøvet. Forskellige amatører og selvudråbte genier har også gjort deres forsøg, og nogle fik endda deres artikler offentliggjort i respekterede videnskabelige tidsskrifter. Disse mennesker har også fremsat nogle overdrevne påstande, ikke hindret af nogen form for viden.
I begyndelsen af dette indlæg nævnte jeg, at jeg blev kontaktet af nogen, der hævdede at have dechifreret manuskriptet. Denne person ser ud til at være en forskningsassistent inden for biologi. Efter en bølge af kritik, der kom efter hans ”opdagelse” blev offentliggjort, har hans universitet distanceret sig fra denne medarbejders påstande. Denne biolog og sproglig amatør argumenterede (efter sit eget syn beviste han faktisk) at det var skrevet på en slags kreoliseret eller blandet gammelt romansk sprog. Og da jeg er kreolist, skrev han til mig. Desværre har han virkelig ikke en anelse om sprogvidenskab, sprogændring, typologi, kreolske prog, skriftsystemer, fonologi, sproglig terminologi eller romanske sprog, og han mangler den nødvendige færdighed til seriøs sproglig analyse. Hans arbejde er selvmodsigende, fragmentarisk og spekulativ. Kort sagt, han ved ikke, hvad han taler om. Og det er derfor, jeg ikke engang vil nævne hans navn eller arbejde – han er simpelthen ikke værd at få opmærksomhed.
Faktisk har jeg hidtil ikke inkluderet nogle links til noget, der har at gøre med manuskriptet; folk skal bare ikke spilde deres tid på at forsøge at dechifrere den, da det sandsynligvis er en smart hoax. Hvem gjorde det, og hvornår og hvorfor, er hvad der er interessant ved det. Jeg vil dog gerne gøre en undtagelse for denne artikel, der præsenterer en dejlig, objektiv og jordnær oversigt.
Næsten alle andre ting, du finder på nettet, er skrevet af skøre amatører. Og der er meget vrøvl derude.
Hvis du spørger mig, tror jeg, at det er en meget smart praktisk joke, en hoax, sandsynligvis fra 1400-tallet, samme dato som pergamentet og blæk. Hvis det ville have været et rigtigt sprog, i et rationelt og regelmæssigt skrivesystem, ville eksperter for længst have regnet det ud. Der er jo så meget tilgængelig tekst, der er illustrationer, som f.eks. stjernetegnene, der giver ledetråde til indholdet. Det skal være let at knække det. Den blotte kendsgerning, at den ikke er afkodet, betyder, at den ikke kan afkodes. Det er simpelthen en falsk tekst.
Peter Bakker er lingvist ved Aarhus Universitet og interesseret i generelle egenskaber ved verdens sprog. Han kan ikke knække Voynich-manuskriptet, men han kan knække de fleste valnødder med sine blotte hænder.






Den engelske oversættelse af denne artikel førte til en del diskussioner og reaktioner, som kan læses her:
See also the discussion about the above article here:
https://languagelog.ldc.upenn.edu/nll/?p=44374
Jeg er blevet opmærksom på nogle artikler på dansk som udkom omkring samme tid som mit indlæg på Lingoblog.dk
”Mysteriet omkring Voynich-manuskriptet” af Sven Hakon Rossel (Professor i Skandinaviske sprog i Wien), den 17. august 2019 i Flensborg Avis, Side 21.
”Tag med på en rejse bag om verdens mærkeligste bog” af Thomas Djursing, den 16. august 2019 i Ingeniøren Side 16, og den 18. aug 2019 i en netversion:
https://ing.dk/artikel/tag-med-paa-rejse-bag-verdens-maerkeligste-bog-227099
og endda en podcast (fra 10.25 til 20.05), interview med Thomas Djursing.
https://ing.dk/artikel/podcast-stigende-grundvand-mystisk-manuskript-228079
It always puzzles me that people imagine nothing can be understood until the written part of the manuscript is understood.
The same people who say that are perfectly comfortable ‘reading’ the images from a medieval Latin manuscript, even if they have not a word of Latin.
In the same way, they will walk through a gallery and ‘read’ those pictures, too – without even bothering to read the written labels.
Why, then, do they suppose we can know nothing about the manuscript until the written text is translated? The usual argument is that we have to start by imagining some scenario and then hypothesise the meaning of the pictures, before hunting within the hypothetical scenario for something we argue ‘like’ the Voynich pictures.
That’s not even remotely the way we provenance a difficult picture – but that is just another of the many paradoxes in amateur study of this manuscript. Formal methods are adopted by those working on the written text, but scarcely at all when it comes to other aspects of the text: not only the images, but the codicology and palaeography. Claimed ‘translations’ never explain why the codicology, and paleography (let alone the imagery) don’t accord with the time and place for the posited ‘original’.