
I slutningen af februar 2020 sad jeg ved et bord i Interacting Minds Center med en forskelligartet gruppe forskere fra Aarhus Universitet, hvor jeg diskuterede, hvordan man kan forske i de sociale og adfærdsmæssige aspekter af den spirende Covid-19-epidemi. De andre forskeres ekspertise spændte over medie- og informationsstudier, antropologi og etnografi, religionsvidenskab, statskundskab og datalogi. Jeg repræsenterede lingvistik. På det tidspunkt havde Covid-19 (såvidt vi vidste) ikke nået Danmark, og der gik stadig en uge, før WHO officielt ville udpege det til en global pandemi. Vi havde en mistanke om, at denne virus kunne have betydelige konsekvenser for vores liv, men vi kunne aldrig have forestillet os, hvor meget og hvor hurtigt.

Blot få uger senere, den 11. marts 2020 (i dag for to år siden), gik Danmark ind i sin første lockdown, og HOPE-projektet blev til med en bevilling fra Carlsbergfondet. HOPE står for How Democracies Cope with Covid-19, og det bruger en kombination af undersøgelses-, etnografiske og digitale mediedata til at overvåge sociale og adfærdsmæssige aspekter af pandemien i flere forskellige lande, herunder nordiske lande, USA, Storbritannien, Frankrig, Tyskland, Nederlandene og Ungarn. Du undrer dig måske over, hvad en lingvist kan bidrage med til dette projekt. Mens HOPE-projektet falder uden for traditionelle sprogvidenskabelige forskningsemner om sprogsystemer eller grammatik, er meget af de data, vi arbejder med, af sproglig karakter, herunder interviewudskrifter, nyhedsdækning og opslag på sociale medier. Derfor er metoder inden for datalingvistik og Natural Language Processing afgørende for at udtrække, opsummere, kvantificere og analysere information fra disse enorme mængder af tekstlige naturlige sprogdata.

Et af de vigtigste bidrag fra HOPE-projektet har været regelmæssige rapporter, som opsummerer de seneste tendenser i sociale og adfærdsmæssige reaktioner på pandemien. En del af disse rapporter dækker undersøgelsesresultater. Vores team, baseret på Center for Humanities Computing Aarhus [chcaa.io] bidrager med den seneste analyse af tendenser fra danske sociale medier, især Twitter og Facebook. Hver uge måler vi, hvor stor en andel af alle danske tweets vedrører pandemien; hvad er de mest populære pandemi-relaterede emner, ord og hashtags; hvordan har folk det med pandemi-relaterede emner som mundbind, coronapas og andre restriktioner (sentimentanalyse); og hvilke kollokationer er der mest brugt i forhold til disse ord (bigramanalyse). Du kan se og interagere med disse resultater på et web-dashboard her for de danske Twitter-data: https://webservice2.chcaa.au.dk/hope-twitter-analytics/da/
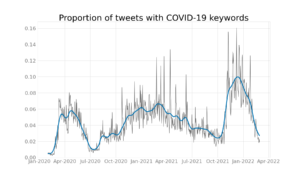
Danmark har tiltrukket sig international opmærksomhed de seneste måneder på grund af sin stigning i omicron-smittetal(hvor der blev anslået at 60 % af alle voksne danskere er blevet smittet) og landets kontroversielle beslutning om at ophæve alle restriktioner fra den 1. Februar, midt i en periode med rekordhøje infektionstal. For at spore, hvad verden siger om Danmark i denne tid, har vi også samlet alle engelsksprogede Tweets, som nævner Danmark og corona/covid/omicron siden november 2021. Du kan interagere med disse resultater her: https://webservice2.chcaa. au.dk/hope-twitter-analytics/da/
Et træk ved europæiske databeskyttelseslove (GDPR) er, at opslag på sociale medier normalt falder ind under kategorien “følsomme data”, hvilket betyder, at vi kan offentliggøre kvantitative resultater, men vi kan ikke offentliggøre individuelle tweets. Dette kan være frustrerende, når man vil undersøge og ræsonnere om individuelle tweets. Jeg fandt for nylig på en temmelig eksperimenterende og uortodoks måde at omgå denne forhindring: at træne en stor neural sproggeneratormodel (GPT-Neo) på vores datasæt af positive, neutrale og negative engelsksprogede tweets om den danske covid-19 situation for at producere nylavede tweets, der tilnærmer mønstre i dataene. Dette giver os mulighed for at offentliggøre eksempler på den slags argumenter og påstande som folk fremsætter (og det sprog, de bruger) i detaljer, uden at gå på kompromis med privatlivets fred.
Vi kan snart frigive en anden web-app, hvor offentligheden kan interagere med GPT-Neo-modellen ved at give den input (f.eks. “Danmarks covid-19-politik er…”, “Vacciner er…”) og lade modellen autofuldføre teksten. (Det svarer til Write with Transformers-appen, som er baseret på GPT-2. Det kan tilgås her: https://transformer.huggingface.co/doc/gpt2-large
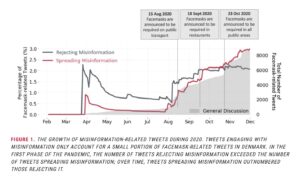
Til dato har vi samlet mere end 40.000 offentlige danske Facebook-opslag, 30 millioner danske tweets, 60 millioner svenske tweets og 15 millioner norske tweets fra februar 2020 og frem til i dag. Alene de sociale mediers datasæt repræsenterer et væsentligt bidrag til både den historiske optegnelse og tilgængelige digitale korpus til lingvistisk forskning og har bidraget til vigtige offentlige ressourcer for dansk som Danish Gigaword Project, en samling dansk tekst på over en milliard ord fra en lang række forskellige registre og genrer. Vores Twitter-data er også for nylig blevet brugt i en undersøgelse om misinformation med hensyn til mundbind i Danmark.
Derudover har de nødvendige analyser til HOPE-projektet krævet, at vi forbedrer og udvikler eksisterende modeller af Natural Language Processing og metoder til sprog, hvor der endnu er få ressourcer, som dansk, herunder forbedring af enhedsgenkendelse og løsning på co-reference gennem nye annotationssamlinger. Vi skulle også komme med nye teknikker til tværlingvistisk anvendelse af værktøjer som sentimentanalyse, d.v.s. hvordan følelser spiller en rolle.
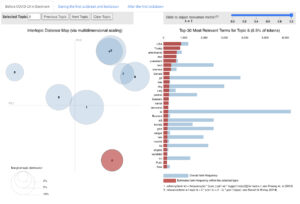
Vi har også fået adgang til omfattende daglig nyhedsdækning for pandemiperioden fra alle større danske, norske og svenske aviser. Til analysen af daglige nyhedsmedier har vi satset stærkt på en teknik kaldet topicmodellering til automatisk at gruppere dokumenter efter deres aktuelle ligheder. Vi udgav et interaktivt dashboard, som giver folk mulighed for at udforske, hvordan den aktuelle fordeling af emner adskilte sig i syv store danske aviser, før, under og efter den første lockdown i 2020.
Topic-modeller blev også brugt til at samle crowdsourcede refleksioner over pandemiens indvirkning på menneskers dagligdag i det interaktive kunstprojekt We Used To, som var et samarbejde mellem HOPE og Studio Olafur Eliasson i Berlin.

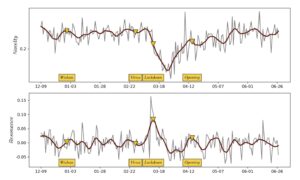
I vores nye medieforskning har vi også brugt topicmodeller som latente (dvs. skjulte) variable i en analyse af informationssignaler i den daglige nyhedscyklus. Intuitivt behandler vi nyhedsmediers dækning af Covid-19 som et naturligt eksperiment i, hvordan kulturelle informationssystemer reagerer på katastrofer. Fordi variation i avisers ordbrug er følsom over for dynamikken i naturlige og sociokulturelle begivenheder, kan den derfor bruges til at måle, hvordan en katastrofal begivenhed forstyrrer nyhedsmediernes almindelige informationsdynamik. Du kan læse vores preprint (på engelsk) om denne tilgang eller se en video af mit foredrag ved sidste års Covid-19 Datathon.
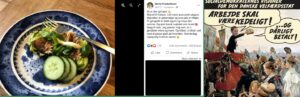
Endelig har jeg for nylig haft fornøjelsen af at samarbejde med min kollega lingvist Alexandra Kratschmer fra Aarhus Universitet om at kombinere beregningsmetoder og traditionel diskursanalyse for at analysere de retoriske strategier, som Mette Frederiksen brugte på hendes offentlige Facebook-side i pandemiperioden og den offentlige modtagelse af hendes indlæg. Det inkluderer det berygtede makrelmad-indlæg, som lancerede tusind memes. Hold øje med Lingoblog for et fremtidigt fælles indlæg om dette arbejde.
Da jeg blev sprogforsker, havde jeg aldrig forestillet mig, at jeg skulle bruge to år på at bidrage til et tværfagligt forskningsprojekt om en smitsom virus og lave rapporter, der konsulteres af den danske statsminister og regeringen med henblik på politiske beslutninger. Men oplevelsen har ikke været andet end givende. At kunne bruge mine færdigheder som datalingvist til et projekt med en så hastende og social virkning har givet mig en følelse af mening gennem disse svære to år.
Et andet vidunderligt aspekt ved HOPE er, at det har givet mig mulighed for at ansætte, vejlede og samarbejde med mange dygtige studerende fra Lingvistik, Kognitionsvidenskab, Kognitiv Semiotik og Engelsk på Aarhus Universitet, som har anvendt deres sproglige og lingvistiske ekspertise samt kodningsevner.
Ikke desto mindre håber jeg, at det presserende behov for pandemisk medieovervågning snart vil ophøre, så jeg kan vende min opmærksomhed tilbage til centrale sproglige emner, der ligger mig nært — emner inden for semantik og variation i lydsymboliksystemer på vestafrikanske sprog. Måske kommer du til at læse om disse emner i en kommende Lingoblog indlæg.
Rebekah Baglini arbejder som datalingvist ved Aarhus Universitet, tilknyttet faget lingvistik ved Institut for Kommunikation og Kultur og Interacting Minds Center.
 Har lingvister vundet årets forskningskommunikationspris? Er der HOPE? Håb?
Har lingvister vundet årets forskningskommunikationspris? Er der HOPE? Håb?  Ny sprogteknologi: Få din egen personlige lomme-Søren Brostrøm
Ny sprogteknologi: Få din egen personlige lomme-Søren Brostrøm  Verdens første Twitter-konference om lingvistik – nu på lørdag!
Verdens første Twitter-konference om lingvistik – nu på lørdag!  Zoom-fatigue — hvad ved vi fra samtaleanalysen? Lingoslam 2019: and the winners are….
Zoom-fatigue — hvad ved vi fra samtaleanalysen? Lingoslam 2019: and the winners are….  Live-forelæsninger om lingvistik på internettet: Lingoblogger er på d. 7. juni
Live-forelæsninger om lingvistik på internettet: Lingoblogger er på d. 7. juni